Splunk 활용 데이터 분석
Splunk는 빅데이터 분석 플랫폼답게 수집된 데이터를 가지고 분석을 할 수 있습니다
가장 큰 장점 중 하나인 검색을 통한 분석 방법인데, 타 플랫폼과의 차별화를 느낄 수 있습니다.
시계열 기반으로 데이터를 검색하되 RDBMS와 같은 쿼리문을 통해 조건절을 입력하고, 해당 내용을 시각화까지 구현하여 보고서에도 용이하게 쓸 수 있습니다.
검색 방법은 다음과 같고 파이프라인을 통해 커맨드를 완성합니다.

기본 명령어
> fields
- 특별한 필드만 검색 시 사용하는 명령어 ( 필드 명 앞에 – 를 붙일 시 대상 필드를 제거 )

> table
- 원하는 필드정보를 그리드(표) 형태로 표시할 때 사용하는 명령어

> rename
- 지정된 필드의 이름을 변경합니다. 필드를 여러 개 지정할 경우 와일드카드(*) 를 사용할 수 있습니다.

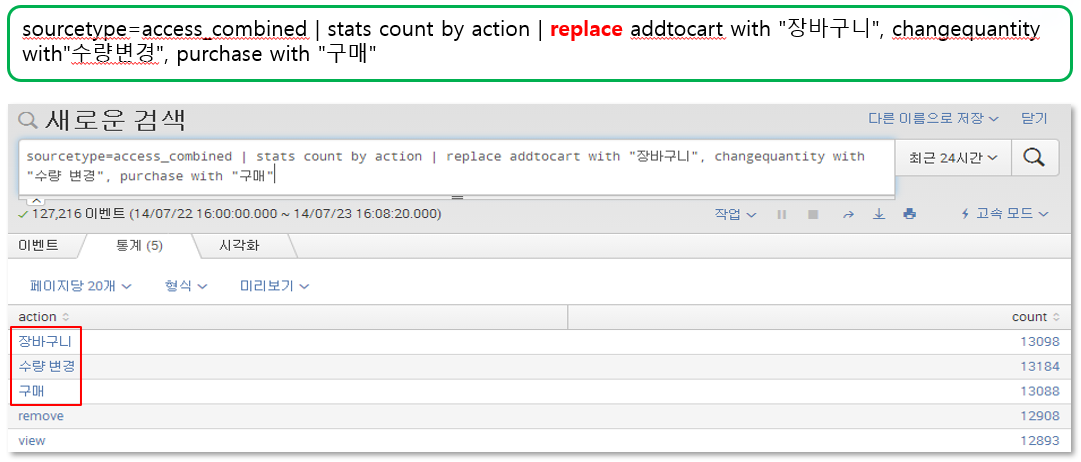
> replace
- 필드 값을 원하는 값으로 치환
> where
- 조회 조건에 맞는 검색 수행

> dedup
- 지정된 기준과 일치하는 최신 결과를 보여 주고 중복을 제거해 주는 필터링 명령어

> sort
- 지정된 필드를 기준으로 검색 결과를 정렬

> top, rare, head, tail
- 지정된 필드의 상위 값을 계산

- 지정된 필드의 드문 값을 계산

- 지정된 결과의 첫 번째 n개를 반환

- 지정된 결과의 마지막 n개를 반환

> eval -if
- 지정된 식을 계산하고 필드에 결과 값을 넣음

> eval -case
- 지정된 식을 계산하고 필드에 결과 값을 넣음

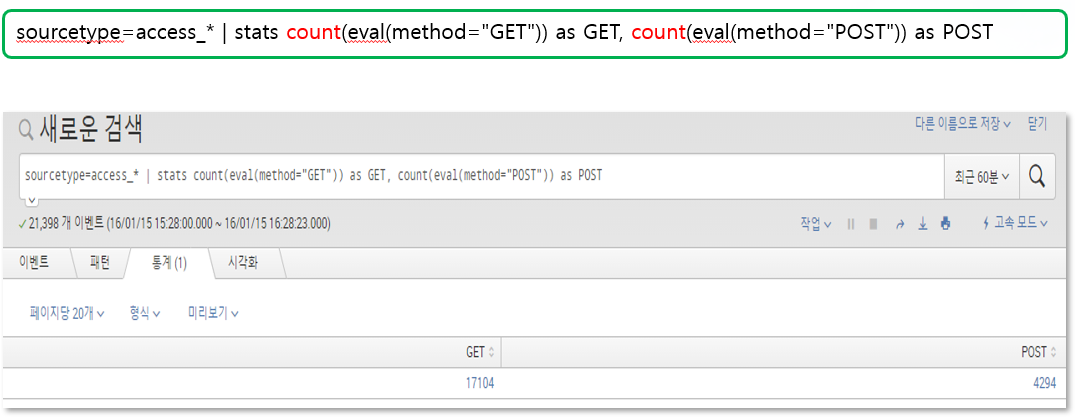
> stats 구조
- 시각화에 가장 많이 쓰이며 분석 대상의 비교 분석 명령어

- stats 함수 종류

> count
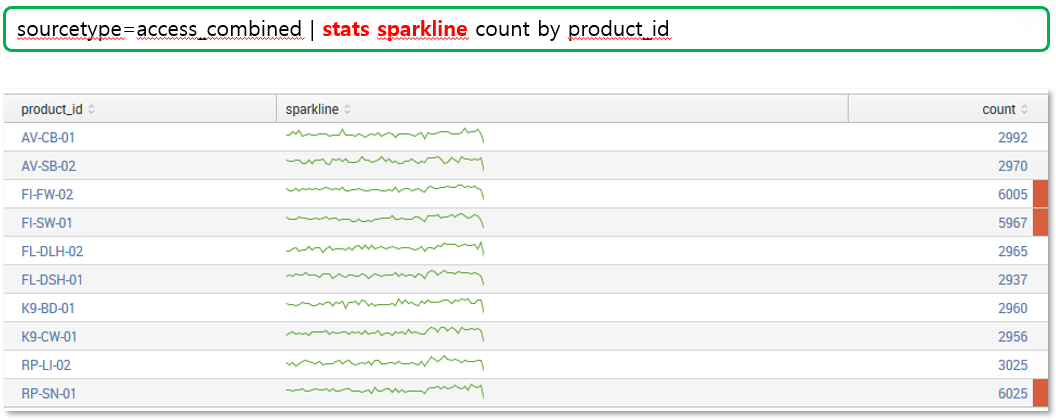
> sparkline
- stats 명령어를 통한 추이 및 합산 적용 결과
> chart

> timechart

> join


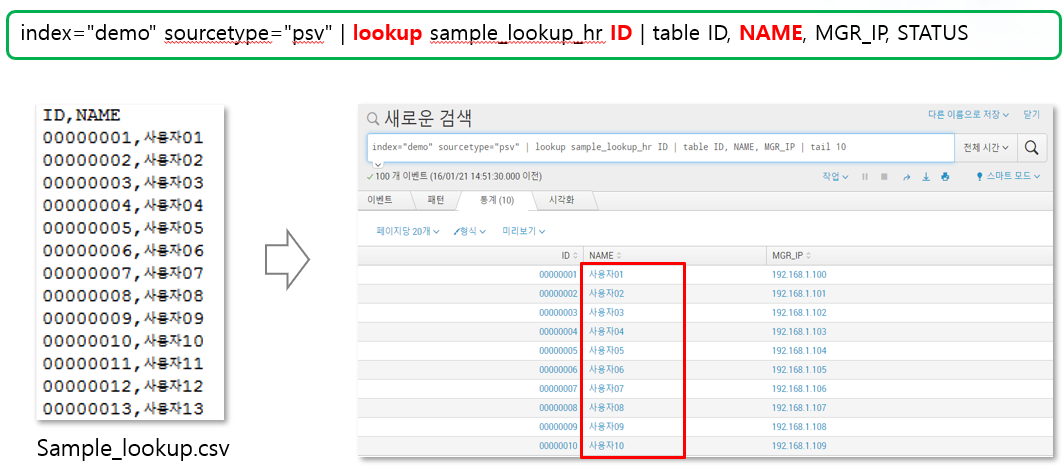
> lookup
- 스플렁크에 저장된 데이터와 외부 파일(DB)에 있는 데이터와 연계하여 상관 분석할 때



> collect
- 쿼리 결과 값을 요약하여 인덱스에 저장

> ealiest, latest
- 검색문에 가장 많이 쓰이는 조건 중 하나이며, 시간 값을 쿼리로 작성하는 구문이다. 이 구문을 설정하면 가장 우선으로 시간 범위가 적용된다.

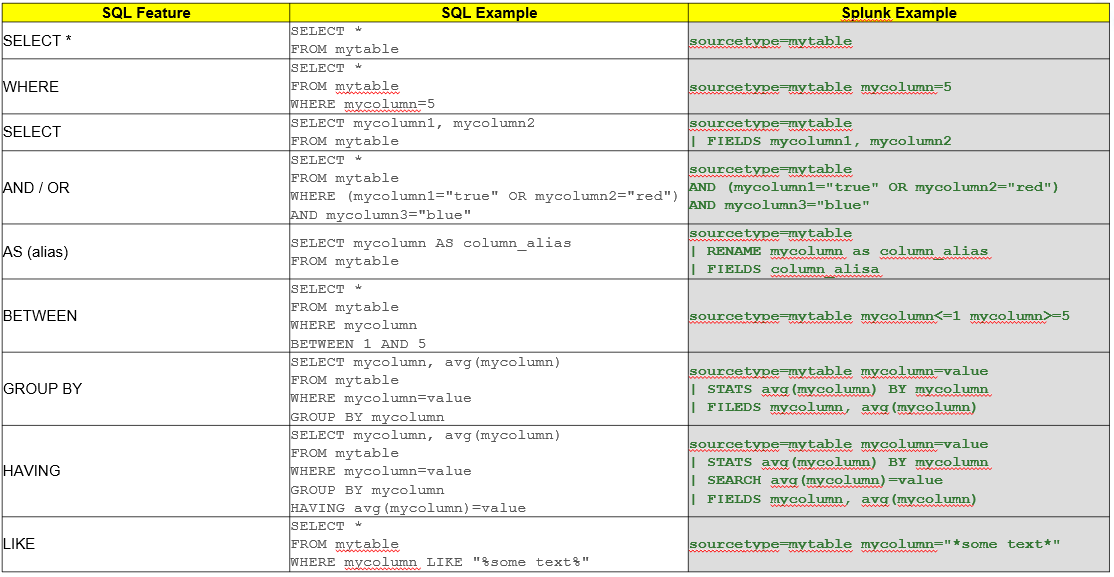
DB Query 와 SPL 비교

'BigData > Splunk' 카테고리의 다른 글
| [Splunk] Splunk Data Model, Accelerate 만들기!! - 데이터 모델 개념과 가속화 (0) | 2021.02.21 |
|---|---|
| [Splunk] Splunk App, Dashboard 만들기!! - 앱과 대시보드를 통한 시각화 구현 방법 (0) | 2021.02.03 |
| [Splunk] 필드에 대해 알아보기!! - 필드추출, 정규식, 구분자 방법 설 (0) | 2021.02.01 |
| [Splunk] Splunk 데이터 수집 해보기!! - 본격적으로 알아보기 (0) | 2021.01.30 |
| [Splunk] Splunk 설치 방법과 UI 알아보기!! - 기본편 (0) | 2021.01.30 |



